
アンペアSMユニットをよく見ると、各ブロックは128個のFP32ユニットで構成されています。しかし、2つのFP32データパスのうちの1つは、INT32演算を同時に実行することもできます。Tensorコアは4つのユニットで構成されており、SMあたり4つのテクスチャユニットと1つのRTコアがあります。

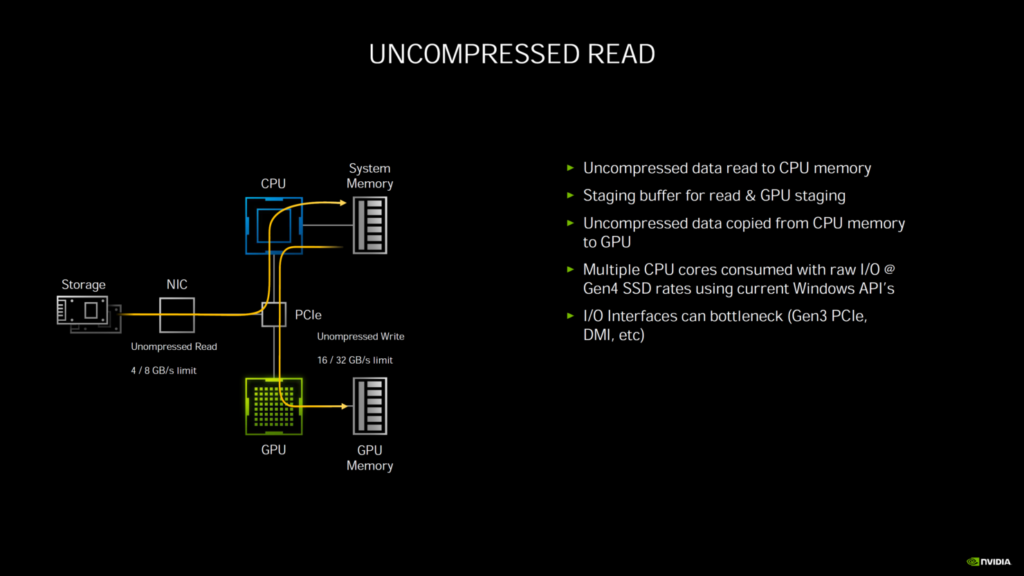
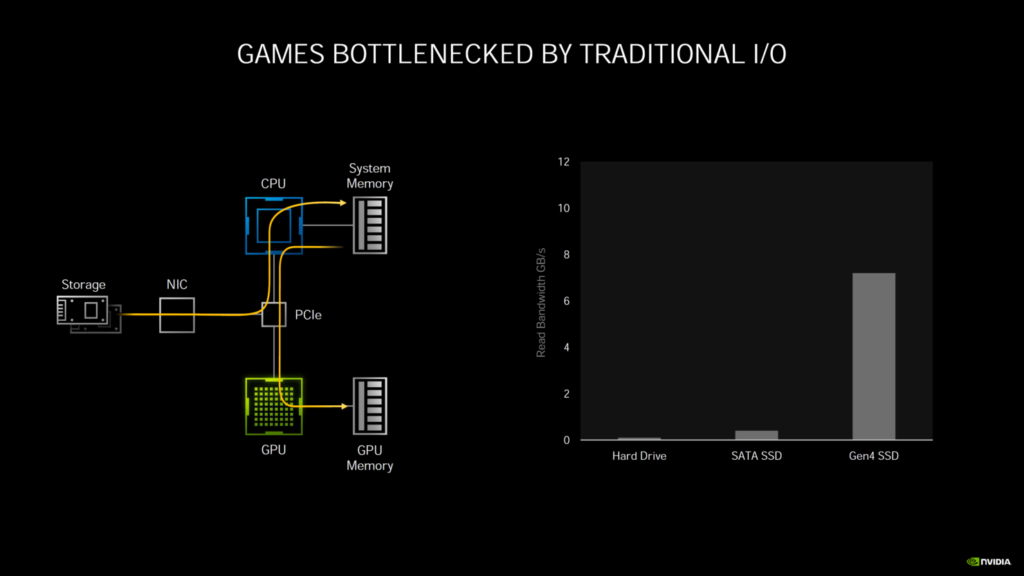
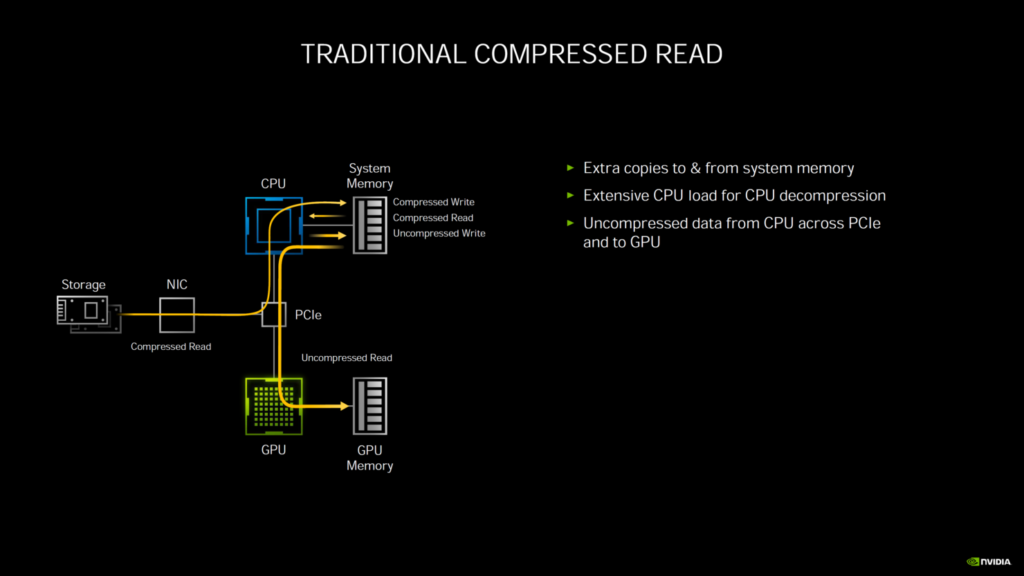
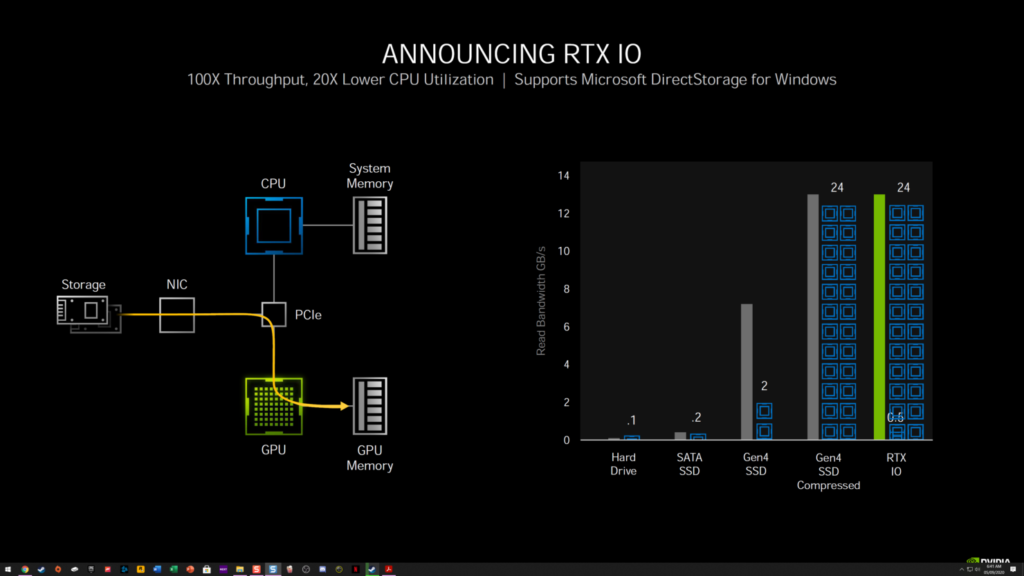
第3世代のTensorコアについては、NVIDIAは、GPUのAmpere HPCラインで使用されているのと同じスパース・アーキテクチャを使用しています。Ampereは、Turingの8個のTensorコア/SMと比較して、4個のTensorコア/SMを特徴としていますが、それらは新しい第3世代設計に基づいているだけでなく、より大きなSMアレイでカウントを増やしています。
Ampere GPUは、INT16コア全体を利用してTensorコアごとに128個のFP16 FMA演算を実行でき、スパースシティがあれば最大256個の演算を行うことができます。SMあたりのFP16 FMA演算の合計は、Sparsityで512、1024に増加しています。Tensorコア設計し直したことで、推論性能の面ではTuring GPUの2倍になったことになります。
同じことがレイトレーシングコアにも当てはまり、2回目のイテレーションでは、Turingアーキテクチャと比較して2倍のレイの交差数を提供します。SMの数が多いほどRTコアの数も多くなりますし、それはAmpereでのレイトレーシングアクセラレーションの全体的な性能にも影響します。
GDDR6X — NVIDIAのGeForce RTX 30シリーズグラフィックスカード専用に設計されたグラフィックスメモリの次なる進化。
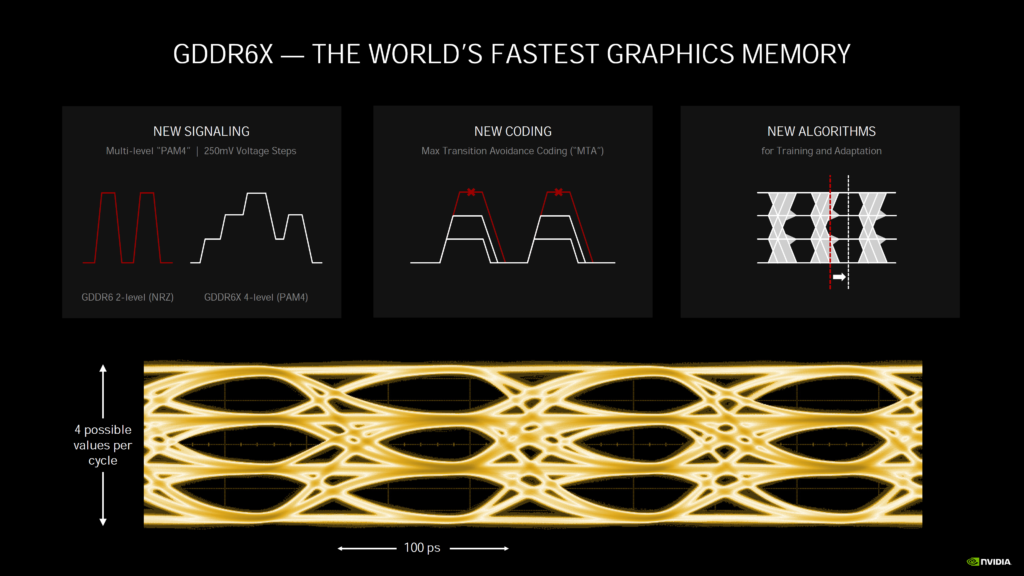
Micron GDDR6Xメモリは、多くの新機能を搭載しています。より高速で、I/Oデータレートが2倍になり、メモリ・ダイにPAM4マルチレベル・シグナリングを初めて実装しました。Geforce RTX 3090クラスの製品では、MicronのGDDR6Xメモリは最大1TB/sの帯域幅を実現しており、8Kなどの高解像度で次世代のゲーム体験を実現するために使用されます。
新しいGDDR6X SGRAMです。
- SGRAMのデータレートを2倍にし、1トランザクションあたりの消費電力を抑えながら、グラフィックスカードアプリケーションのための1テラバイト/秒(TB/秒)のシステムメモリ帯域幅の境界を突破することができます。
- プロセッサとDRAM間で4つの電圧レベルを使用して1インターフェースクロックあたり2ビットのデータをエンコードして転送するPAM4エンコード信号を採用した初のディスクリート・グラフィックス・メモリ・デバイスです。
- 高速で安定した設計・運用が可能で、大量量産で作られる。
前述したように、GDDR6Xは新しいPAM4マルチレベルシグナリング技術を採用しており、データの転送速度が格段に速くなり、I/Oレートが2倍になり、各メモリの能力を64GB/sから84GB/sに押し上げています。
Micron GDDR6Xメモリダイは、PAM4シグナリングを搭載しながら量産可能な唯一のグラフィックスDRAMでもあります。

興味深いのは、MicronがそのGDDR6Xメモリが21Gbpsまでの速度を打つことができることを引用しているのに対し、我々はGeForce RTX 3090のアクションで19.5Gbpsを見るようになっただけです。AIBが利用できるようになれば、より高いビンディングダイを利用できるようになる可能性が高いと思われます。
Micronはまた、2021年には21GB/s以上の速度を提供することを計画していることを確認していますが、将来的にグラフィックスカードに採用されるかは明らかではありません。
単に速度が速いだけでなく、MicronのGDDR6Xは、前世代のGDDR6メモリと比較して転送ビットあたりの電力を15%削減しながら、より高い帯域幅を提供しています。
Micron GDDR6X Memory
| Feature | GDDR5 | GDDR5X | GDDR6 | GDDR6X |
|---|---|---|---|---|
| Density | From 512Mb to 8Gb | 8Gb | 8Gb, 16Gb | 8Gb, 16Gb |
| VDD and VDDQ | Either 1.5V or 1.35V | 1.35V | Either 1.35V or 1.25V | Either 1.35V or 1.25V |
| VPP | N/A | 1.8V | 1.8V | 1.8V |
| Data rates | Up to 8 Gb/s | Up to 12Gb/s | Up to 16 Gb/s | 19 Gb/s, 21 Gb/s, >21 Gb/s |
| Channel count | 1 | 1 | 2 | 2 |
| Access granularity | 32 bytes | 64 bytes 2x 32 bytes in pseudo 32B mode | 2 ch x 32 bytes | 2 ch x 32 bytes |
| Burst length | 8 | 16 / 8 | 16 | 8 in PAM4 mode 16 in RDQS mode |
| Signaling | POD15/POD135 | POD135 | POD135/POD125 | PAM4 POD135/POD125 |
| Package | BGA-170 14mm x 12mm 0.8mm ball pitch | BGA-190 14mm x 12mm 0.65mm ball pitch | BGA-180 14mm x 12mm 0.75mm ball pitch | BGA-180 14mm x 12mm 0.75mm ball pitch |
| I/O width | x32/x16 | x32/x16 | 2 ch x16/x8 | 2 ch x16/x8 |
| Signal count | 61 – 40 DQ, DBI, EDC – 15 CA – 6 CK, WCK | 61 – 40 DQ, DBI, EDC – 15 CA – 6 CK, WCK | 70 or 74 – 40 DQ, DBI, EDC – 24 CA – 6 or 10 CK, WCK | 70 or 74 – 40 DQ, DBI, EDC – 24 CA – 6 or 10 CK, WCK |
| PLL, DCC | PLL | PLL | PLL, DCC | DCC |
| CRC | CRC-8 | CRC-8 | 2x CRC-8 | 2x CRC-8 |
| VREFD | External or internal per 2 bytes | Internal per byte | Internal per pin | Internal per pin 3 sub-receivers per pin |
| Equalization | N/A | RX/TX | RX/TX | RX/TX |
| VREFC | External | External or Internal | External or Internal | External or Internal |
| Self refresh (SRF) | Yes Temp. Controlled SRF | Yes Temp. Controlled SRF Hibernate SRF | Yes Temp. Controlled SRF Hibernate SRF VDDQ-off | Yes Temp. Controlled SRF Hibernate SRF VDDQ-off |
| Scan | SEN | IEEE 1149.1 (JTAG) | IEEE 1149.1 (JTAG) | IEEE 1149.1 (JTAG) |
ページ3へ
















コメントを残す